
My Approach to Audio AR
When I begin creating a new audio AR piece, there are a handful of questions I ask myself that help me hone in on the best approach to the project as well as make sure I consider a broad set of options. Typically I have preconceived notions about what the piece needs to be, but I have found that going through these questions is a useful exercise even if it doesn’t end up changing my approach to anything. This is surely an incomplete list, but a starting place nonetheless.
As an example, I will refer to a project I am currently working on to make these decisions and thought-processes more concrete. The project is called One Square Mile, 10,000 Voices (co-produced with Sue Ding) and is an exploration of the personal histories of Japanese Americans incarcerated at the Manzanar concentration camp outside of Los Angeles during World War II. I am actually on the plane flying back from attending the 50th Manzanar Pilgrimage as I write this; I’ll do a more in-depth write-up of the project once it is further along and available to the public, but for now, it will serve as a case-study of sorts.
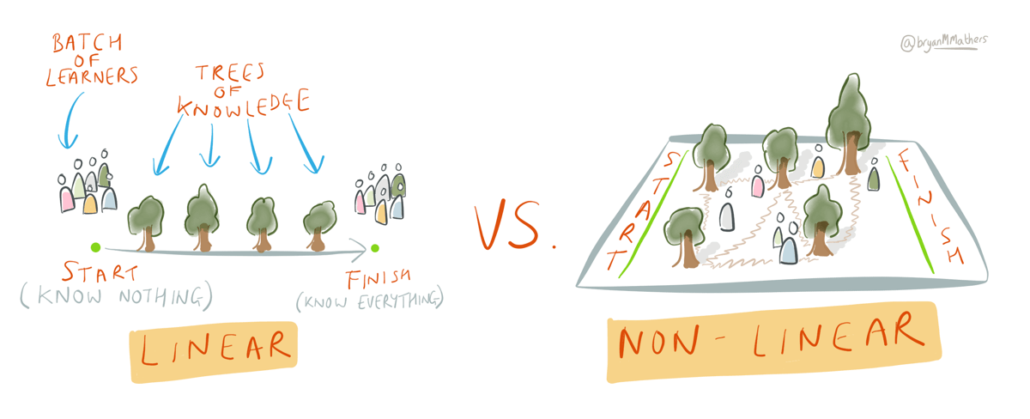
Linear vs. Non-Linear
One of the most interesting aspects of audio AR to me is the ability to create non-linear experiences that are different for each individual experiencing them. Of course, non-linearity isn’t a requirement for audio AR, so I always consider what sort of experience I want to create and what degree of linearity makes sense to accomplish the intended goal. Is there a story or narrative that requires a clear beginning, middle and end? Or is the experience more open-ended and exploratory or might it benefit from the unpredictability of listener inputs (i.e. path they walk, movements they make etc)?
Might it benefit from the unpredictability of listener inputs?
I am a fan of non-linearity and think that compelling stories can be told letting the listener connect bits and pieces into a meaningful whole without presenting them in an order that “makes sense”. Sometimes things that don’t make obvious sense end up being more thought-provoking, memorable and ultimately more personal.
For the Manzanar project, I have access to several thousand hours of oral histories from Japanese Americans who were incarcerated in the camp. They each have an amazing story to tell, but I want to try to communicate a more communal and broad story of life in the camp, so a non-linear approach makes more sense than trying to recreate individual lives. Additionally, the camp where I will be distributing the voices is quite open and doesn’t have specified paths that visitors are required to travel on, so encouraging listeners to wander where they want to physically while discovering more and more pieces of the whole story feels right to me.
I do plan to add some linear features into the experience by introducing content into the mix based on the duration of an individual listener’s experience. In other words, more content is “released” the longer an individual listens.
Should it be Contributory?
Do I want people to be able to contribute their voices or other recordings to the piece? If so, will those recordings be made prior to the release of the piece and incorporated directly by myself? Or will I allow people to make and add their own recordings to the piece while the piece is live and available for consumption? What sort of control do I want to be able to have over the evolution of the piece? Do I want listeners to not only be able to influence the piece by their movements and actions, but also by leaving persistent traces of their unique experience via recordings for other participants to hear?
Leaving persistent traces of their unique experience…
When I decide to open up my projects to participant commentary, I am opening up my project for people to contribute amazing inspirational things, but also to be disrespectful and contribute comments that detract from the experience. Deciding how to moderate the content (I strongly prefer post-moderation) and establishing some guiding principles for what sort of contributions would be considered inappropriate is crucial.
I have a strong preference for primary source material as well, so when I ask people to contribute to my pieces, I tend to ask questions that elicit direct personal responses about individual experiences rather than reflections or interpretations of things they have heard or learned from others.
If I was focused only on re-creating and conveying what life was like at Manzanar, I would probably choose to curate all of the content myself and not allow participants to add to the piece with their own contributions. But a large part of this piece is to make a connection between the way Japanese Americans were treated in the 1940s in America and the way Muslim Americans, refugees and immigrants in general are being treated in America today. In order to emphasize this connection, I want to bolster the piece by allowing participants to reflect on their surroundings in the camp and what they have heard and how it relates to their own lives. I will be posing several questions for participants to consider responding to and those audio responses will be left on-site for other listeners to hear thereafter.

What Audio Layers / Content Categories?
One of the defining characteristics of audio AR is the ability to layer audio on top of physical space, but this leaves tons of possibilities for exactly how to do this. How many layers of audio would be best? What sort of content is in each layer of audio? How many layers can be heard at once?
For me, it is crucial to create a continuous audio experience for listeners; otherwise, I find that audio clips can seem out of place and jarring as they emerge from silence. Immersion is important to me and continuous audio allows listeners to get into a flow of experience. I think of a continuous base of audio as the glue that holds together the experience.
So a continuous base layer of music or ambient audio is one layer.
Audio clips can seem out of place and jarring as they emerge from silence…
And then what happens on top of this? Are there layers of user-contributed content? Are there sound effects or environmental recordings? Are their spoken voices? Sung voices? Anthropogenic sounds? The list goes on and when I think about distributing audio over a physical space, I consider very carefully what sort of sounds I want to include and whether or not those need to be treated similarly of differently from each other in the experience.
At Manzanar, I am not sure what will end up being the best combination, but my thoughts at present are to have these layers:
- base layer of some ambient musical audio; probably not overly melodic or rhythmic and composed to be supportive rather than prominent
- Location-specific ambient sounds: things like the sounds of a basketball being dribbled overlaying the outdoor basketball court; sounds of a cafeteria in the location where the cafeteria used to stand.
- Oral histories of former incarcerees: this will likely be the bulk of the content
- Period audio: news, propaganda from WWII
- Present-day news/commentary relating to immigration, racial justice etc
- Participant contributions
How exactly these layers will be distributed over space and time will require a lot of experimentation; but that’s the fun part.
Absolute vs Relative Location?
Some audio AR projects are directly related to a specific landscape. Others are related more to a movement through or interaction with the landscape; they have no requirement for a specific landscape and can benefit from being experienced in differing landscapes. I consider the former to be “absolute” and the latter “relative”.
This is usually a fairly straight-forward decision for me as it tends to be clear from the content of the piece whether it relates directly to a specific landscape or not. A piece about the architecture of Chicago should probably exist on the streets of Chicago whereas a piece about the solar system could be experienced in any relatively open space. I do, however, often struggle with the accessibility of absolute location-based pieces. Not everyone can get to the specific location and might there be a way to broaden the accessibility of the piece by allowing for off-site access in some different form?
We want to retain the core concept and emotional affect of the piece across on-site and off-site experiences, and aim to complement the core on-site experience, not reproduce it elsewhere.
The core of the Manzanar piece is clearly suited for absolute location given the direct connection of the oral history content to the landscape of the camp itself and the intention of those to reinforce each other. Sue and I are currently thinking about ways to allow access to some form of the experience without requiring people to fly to LA and then drive 3.5 hours north into the Owens Valley to the middle of nowhere. What can be conveyed when not on-site? How can the strengths of different forms of media (ie website) be used to communicate effectively while not on site? We want to retain the core concept and emotional affect of the piece across on-site and off-site experiences, and aim to complement the core on-site experience, not reproduce it elsewhere.

Directional and/or Locational Audio?
Locational audio is audio you hear only when physically within a pre-defined geographic region assigned to that particular audio.
Directional audio is defined as audio that is panned in your stereo field to give the effect that it is coming from a certain physical location. If the listener turns their head or points their device to a different place, the audio is panned accordingly. Directional audio is essentially the creation of “sound objects” – glossary link – that represent objects in physical space that emit audio. These objects can be stationary or mobile, just like IRL; a tree can emit a sound or a car can drive by you from left to right.
Clearly, these are not mutually exclusive; quite often the combination of the two will create the most realistic facsimile of the physical world.
We are still considering the best approach for the Manzanar project. Our test installations have been locational only, but we are considering adding directional as well. Directional can add to the realism of an experience as well as facilitate audio layering by distributing audio in the stereo field, but there are some technical requirements (ie Bose Frames) and UI knowledge (ie users must point their phone in the direction they are looking to preserve the effect) that are required to make it happen. We plan to experiment with directional and see how it feels before making the final decision, though my gut says directional audio will add a compelling dimension to the experience.
What Technology?
Personally, I tend to not have to think too hard about what platform to use since I have developed the Roundware platform to handle the majority of my aesthetic and structural needs for my projects. But just because I am using Roundware, doesn’t mean Roundware does everything I need it to do for any given project and I will admit that I sometimes get stuck in the Roundware paradigm which can shut me off to other interesting possibilities. One of the things I enjoy most about each new project is how I can extend and improve the core Roundware functionality to allow for new and exciting aesthetic and experiential features
I am surely not the best person to recommend other platforms, but Bose AR is interesting and particularly geared towards directional audio and companies like Calvium have experience producing audio AR mobile apps using a platform they have developed.
Beyond platform, there are other technical considerations, including:
- If mobile-based, what platforms to support (iOS, Android, web)
- If not mobile, how best to broadcast the audio?
- How accessible is the technology you require? Will you provide it or use participants` devices?

Duration?
What is the ideal amount of time a listener should engage with the piece? Is there an ideal length of time? What is reasonable to consider people engaging?
Of course, I want people to engage for as long as possible since that makes me feel better about myself(!), but realistically, it is important to think about how long people will likely spend with your piece and then keep that in mind when sculpting the experience. If you think people will spend 10 minutes with the piece, releasing lots of content after they have been listening for half an hour probably isn’t a great idea.
Conclusion
This is far from a comprehensive list of considerations I mull when beginning a new project, but they do tend to be the ones the come up consistently.
Ultimately, the initial decisions you make will likely be over-ridden in some cases and reinforced in others, if you are anything like me. I find that these questions get the creative juices flowing and force me to consider different possibilities that may not otherwise be considered.
So for the Manzanar project, all I have to do now is create a non-linear, contributory, multi-layered, location-based, absolutely positioned, locational and possibly directional audio AR piece using Roundware(!)
Check back with me in the fall and we’ll see how it went…

