The Future of Face-Wear
I’m not sure if that is a term, but “face-wear” seems appropriate for all the crazy things tech companies want us to put on our faces as a portal into digital worlds. I have an assortment of feelings of ambivalence and apprehension about many approaches that are being taken, but overall, there is so much positive potential that I try to stay abreast of where things are going.
To this end, I just read this great article on the current and future state of hardware for VR and AR. It has been a confusing landscape for everyone with the rapid pace of development and seemingly faster pace of deprecation, and this article does a great job of laying out the basics.
SMARTPHONE, MEET SMARTGLASS. NOW TETHER.
This focusses on visual forms of augmentation, but there are implications and interesting points that can be applied to audio AR.
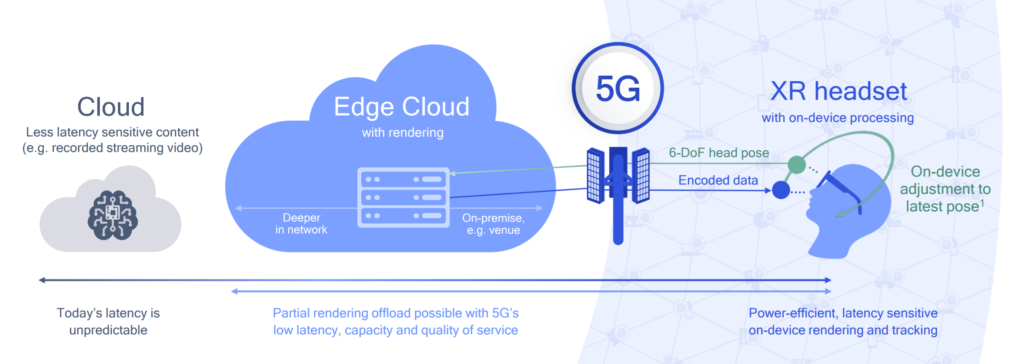
There is a lot of discussion of 5G and how “edge computing” will enable new, more realistic AR experiences and this is super exciting. Moving the computational heavy lifting off the device and into the cloud, while retaining the ultra-low latency of on-board processing via 5G is no doubt hugely significant if and when it is realized with some form of mass-distribution.
Audio has traditionally been way less processor intensive and hence doing audio AR has been “easier” and requiring of less intrusive hardware, but as I delve into experiments with trying to make audio sound like it is coming from a real-world point source, I realize that I may have been deluding myself.
The reason audio AR requires less processing at present may simply be because no one has yet figured out how to do it right.
There is less processing required because less is being done. After all, it takes less processing to display a janky looking pixelated tomato floating randomly in front of you than it does to create an animated Jigglypuff complete with real-world occlusion and shading. Is audio AR in the pixelated tomato phase? Yes, we can pan things generally in 3D space but it hardly sounds like a point source in most cases. And distance emulation is so much more than volume attenuation.
- Who is trying to solve these challenges?
- Are the big tech companies too focussed on visuals to put resources into audio?
- Do we need a complete makeover of audio delivery devices (i.e. ear buds) for this to be possible?
- Or will processor-enabled advances in psycho-acoustics do the trick?
I’m sure efforts are being made to address these questions and I will dive into those and report back when I can.
Check out the entire linked piece, but I’ll leave you an eloquent encapsulation of something I’ve been thinking about for many years, but only now is it starting to become possible.
XR represents a technology communicating to us using the same language in which our consciousness experiences the world around us: the language of human experience.
Pause on that for a moment. For the first time, we can construct or record — and then share — fundamental human experiences, using technology that stimulates our senses so close to a real-life experience, that our brain believes in the same. We call this ‘presence’.
Suddenly the challenge is no longer suspending our disbelief — but remembering that what we’re experiencing isn’t real.
–Sai Krishna V. K
Thank you to Scapic for sharing this!